 Unicode与字节串
Unicode与字节串
# Unicode 与字节串
1.字符编码:
ASCII编码:每个字符存储在一个字节中。字符码值从 0~127Latin-1编码:每个字符存储在一个字节中。字符码值从 0 ~ 255。其中码值 128 ~ 255 分配给特殊字符;码值 0 ~ 127 部分与ASCII编码相同。UTF-8编码:每个字符存储的字节数量可变,不再是固定编码 >ASCII编码是UTF-8编码的子集,也是Latin-1编码的子集2.
Unicode文本通常叫做“宽字符”字符串,因为每个字符可能表示为多个字节3.查看字符的
Unicode码值:ord()函数; 查看Unicode码值对应的字符:chr()函数这里的
Unicode码值都是整数,可以是十进制、二进制、八进制、十六进制整数等

4.Python 大约支持上百中不同的编码。可以导入encodings模块,并运行help(encodings)显示很多编码名称。有一些编码是 Python 中实现的,一些是 C 中实现的。
有些编码对应多个不同的名称

5.Python3 中有三种字符串相关类型:
str类型表示Unicode文本(8 位和更宽的位数),为不可变的字符序列,称为字符串bytes表示二进制数据,称为字节串。bytes对象其实是小整数的一个序列,每个整数的范围在 0 ~ 255 之间。- 索引一个
bytes实例返回一个整数 - 分片一个
bytes实例返回一个新的bytes实例 list(bytes_obj)返回一个整数列表而不是字符列表bytes类型几乎支持所有的str操作,但是不支持字符串格式化操作(没有字节串格式化操作)
- 索引一个
bytearray是一种可变的bytes类型,称为可变字节串。bytearray是bytes的一个变体, 它是可变的且支持原地修改。它支持str与bytes的常见操作,以及与列表相同的一些原地修改操作。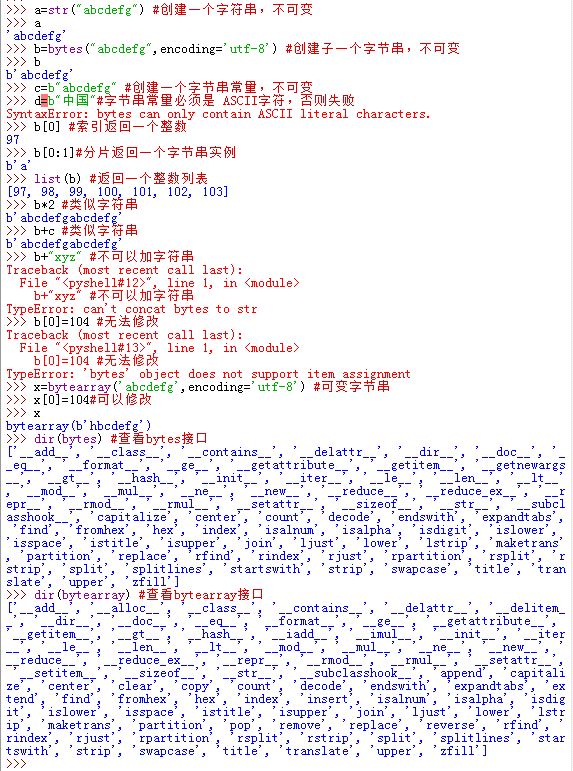
6.
sys.getdefaultencoding()函数返回平台默认的编码方式。sys.getfilesystemencoding()返回系统文件的默认编码方式。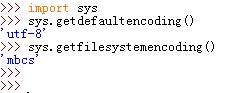
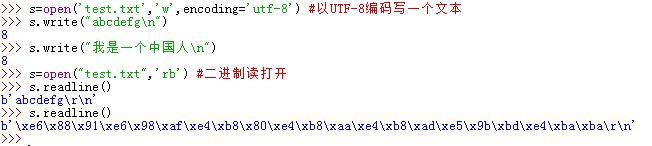
7.Python3 中,当一个文件以文本模式打开时,读取其数据会自动将其内容解码,并返回一个字符串;当一个文件以文本模式写打开时,写入一个字符串会在将该字符串写入文件之前自动编码它。
编码和解码的类型是系统的平台默认编码类型,或者你手动设定的编码类型
根据编码类型,Python 自动处理文件起始处的字节标记序列(通常用于标记文件编码类型)
Python 自动对行尾换行符转换。在 windows 下,换行符
\n在写入文件时转换为 windows 下的换行符\r\n。在读取文件时 windows 下的换行符\r\n转换为标准换行符\n
当一个文件以二进制模式打开时,读取其数据直接返回其原生内容而并不以任何方式解码,也不做任何方式修改(即不转换换行符),直接作为bytes实例返回;写入会接受一个bytes实例或者一个bytearray实例,并且不加修改地写入到文件(即不转换换行符)
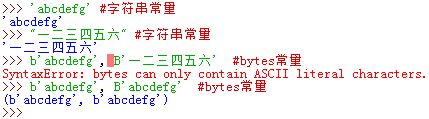
8.在 Python3 中,'xxx'、 "xxx" 、'''xxx'''均创建一个字符串常量,而添加一个b或者B中创建一个bytes常量b'xxx'、 B"xxx" 、b'''xxx'''
尽管
bytes打印出来是字符串(若无对应的字符则输出内存表示),但它本质上是一个小整数序列Python3 中所有字符串都是 Unicode 字符(是 ASCII 字符的超集)
9.Python3 中,虽然字符串与
bytes的内存表示相同,但是二者不能混用,因为二者无法自动转换。对于期待一个str实例作为参数的函数,它不能接受一个bytes实例;反之亦然字符串的
.encode(encoding)方法和bytes的bytes(a_string,encoding)函数将一个字符串实例转换为它原生bytes形式字符串的
str(a_bytes,encoding)函数和bytes的.decode(encoding)方法将一个bytes实例解码成字符串形式。
字符串的
.encode(encoding)方法的encoding参数可以为空,此时表示使用平台默认编码
str(a_bytes)函数返回的是bytes实例的打印字符串,而不是执行编码转换过程

10.Python 的字符串常量支持:
'\xNN':单字节字符(8 位),等价于\u00NN'\uNNNN':双字节字符,16 位'\UNNNNNNNN':4 字节字符,32 位 >这里的N均为十六进制整数的一个整数位[0~F]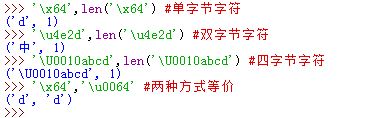
11.编解码 ASCII 字符非常简单,无需显示指定编解码类型(当然你可以随意指定一个编解码类型,因为 ASCII 编码是任何编码类型的子集)

编解码非 ASCII 字符则要注意,对该字符的编码类型必须与解码类型一致,否则乱码或者抛出UnicodeDecodeError。

12.生成 Unicode 字符串你可以通过 Unicode 转义序列来创建,如'A\u4e2d\u56fd';也可以通过chr()函数来创建,如
'A'+chr(0x4e2d)+chr(0x56fd),最终结果都是'A中国'
13.字符串常量与bytes常量区别:
对字符串常量,
'\xNN'与'\u00NN'是等价的;对bytes常量,b'\xNN'与b'\u00NN'是不等的b'\xE8'长度为 2 字节,b'\u00E8'长度为 6 字节字符串常量可以包含任意字符;
bytes常量要求字符要么是 ASCII 字符,要么是转义字符len(string_literal)得到字符串常量的字符个数;len(bytes_literal)得到bytes常量的字节数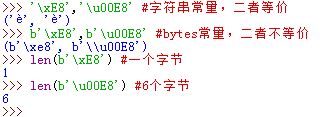
14.指定 Python 源文件字符集编码声明:在脚本的第一行写入:
# -*- coding: latin-1 -*-
15.bytes实例的构造:
b'abc':构造bytes常量bytes('abc',encoding='ascii'):通过构造函数传入字符串和编码构造bytes([97,98,99]):通过传入小整数可迭代对象构造'abc'.encode('ascii'):从字符串编码获取16.
bytearray实例的构造:bytearray('abc',encoding='ascii'):通过构造函数传入字符串和编码构造bytearray(b'abc'):通过bytes常量构造
17.打开文件时,可以通过
encoding关键字参数指定打开文件的编码方式18.Python 的
struct模块可以从字符串创建和提取打包的bytes19.
pickle模块存储pickle化的对象用的是bytes